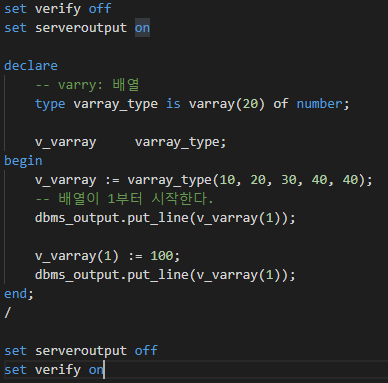
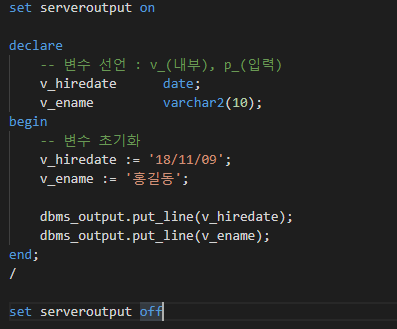
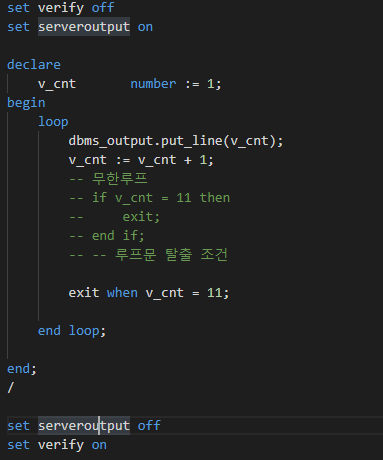
함수 - 그룹함수
그룹 함수
통계와 연관이 깊은 함수

- count(): 행의 개수 측정

간단하게 직원번호를 통해 직원수를 구해보았다.
count로 comm의 개수도 함께 출력해보자.

이 경우 empno는 12가 출력되지만 comm은 4만 출력되고 있다.

이는 comm이 null값을 가지고 있어 실제로 데이터는 4개 뿐이기 때문이다. 즉 count는 null 데이터는 숫자로 넣지 않는다.
이를 위해서 null값을 0으로 바꾸고 count를 사용해보겠다.

이 경우 null 값이 모두 0이 되어 count 함수에 범위에 들어간다.

전체 데이터의 개수 - 이 경우 모든 칼럼을 다 count연산을 진행하고 가장 많은 것을 출력한다.
다음은 sum함수에 대해서 살펴보겠다.
- sum()
전체 합

조건 합

- avg()

이를 조합 해보도록 하겠다. 이 때 데이터의 개수는 12개이다. 따라서 sum을 12개로 나눈것과 count로 나눈 것, 그리고 avg를 이용해서 구한 거을 비교해보자.

출력화면을 확인하면 avg와 count를 이용한 경우와 단순하게 데이터의 개수로 구한 값이 다르다. 이는 count와 avg는 null값을 카운트 하지 않는다. 따라서 다른 값이 출력된다.
따라서 평균을 구할 때 null을 넣을지 버릴지에 대해 생각하고 이에 맞춰 함수를 사용하자.
만약에 avg를 이용하여 전체 데이터 개수를 반영하고 싶다면, nvl()함수를 통해 null값을 0으로 바꾸자.

- max() / min()

만약에 max를 사용하여 가장 월급이 많은 사람의 이름을 추출하고 싶다.

하지만 max는 집합 함수이다. 따라서 집합이 적용될 경우 개개인의 특성에 대해서는 지워버린다. 따라서 다음의 형식을 사용할 수 없다.
댓글
댓글 쓰기