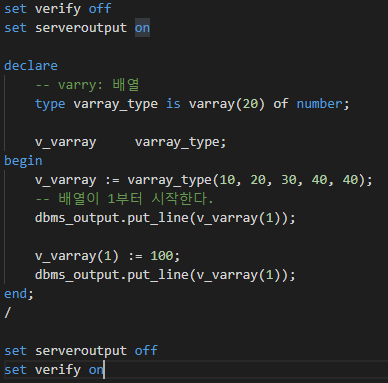
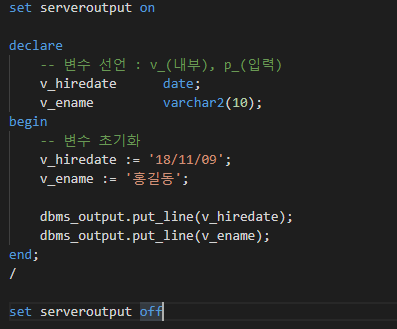
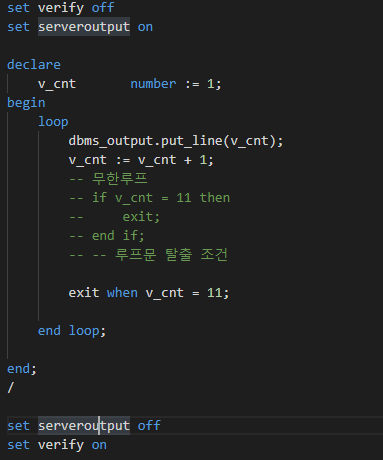
데이터베이스 집합 연산자 - rollup / cube
Rollup과 Cube
Rollup과 cube는 group by에 의해서 출력되는 부분집계 결과에 누적된 부분 집계를 추가해준다. 이 때 rollup은 그룹화할 때 좌측 칼럼에서 우측칼럼으로 진행한다는 것을 명심하자.
rollup

위의 예시에서 rollup(deptno, job)은 (deptno, job), (deptno), () 그룹으로 분류가 되어 각 그룹을 group by하여 부분 집계 한다.
따라서 위에서 다뤘던 세 가지 패턴의 그룹으로 select한 것들을 union으로 집합 연산한 결과와 동일하게 출력된다.

cube
여기서 더 나아간 것이 cube이다. cube는 (deptno, job)으로 구성할 수 있는 모든 부분집합에 대해서 부분 집계를 추가한다. 따라서 rollup과 달리 (job)이라는 부분집합도 추가된다.

따라서 cube를 이용하면 다음처럼 job을 통해서 그룹화한 select문이 추가된다고 생각하면 된다.

rollup과 cube를 통해서 그룹화할 때 각 부분집합에 대해서 별도의 select문을 통해서 그룹화를 추가하고 이를 집한 연산으로 묶는 것과 달리 보다 간편하게 부분집계와 누적집계를 각 부분집합에 대해서 한번에 처리할 수 있다.
Grouping 함수
그룹핑 함수는 반드시 rollup 또는 cube와 함께 사용하는 함수이다. 이를 통해서 각 부분집계에 대해서 어떤 칼럼이 연산과 연관되었는지를 구별할 수 있다. 연관될 경우 1, 그렇지 않을 경우 0을 출력한다.

Grouping sets
grouping sets는 group by를 확장한 것으로서 rollup 또는 cube가 지정된 원칙에 따라 칼럼들을 그룹화하는 것과 달리 사용자가 원하는 칼럼으로 구성된 그룹을 생성할 수 있다.
아래 예시를 보면, 이 명령문은 (deptno, job, mgr), (deptno, mgr), (job, mgr) 세 가지의 경우에 대해서 그룹핑 하고 있다.

우리가 선택해준 (deptno, job, mgr), (deptno,mgr), (job,mgr) 순으로 그룹핑한 데이터들을 출력하고 있다.
복합 칼럼 처리
rollup과 cube에서 칼럼을 처리할 때 여러 칼럼에 대해서 하나의 단위로 처리하도록 만드는 방법이다. 구현은 간단하게 원하는 칼럼들을 () 안에 묶어 사용한다.
예를 들어, rollup( a, (b, c), d) 가 있을 경우, b와 c는 하나의 단위로만 처리된다. 따라서 이 때 그룹핑이 (), (a), (a, b, c), (a, b, c, d)에 대해서 이루어진다.
cube( a, (b, c), d)의 경우에는 (), (a), (b, c), (d), (a, b, c), (a, d), (b, c, d), (a, b, c, d)로 그룹핑이 이루어진다.
아래의 예시는 결국 (), (deptno), (deptno, job, mgr)로 그룹핑이 되고 있다.

()는 전체를 그룹핑하여 총 임금을 계산한다. 그리고 (deptno)는 부서별로 그룹핑하여 sum을 계산하여 부서별 총 임금을 출력한다. 마지막으로 (deptno, job, mgr)을 통해 그룹핑하고 있다. 부서별 직책별로 그룹핑을 하고나면 mgr은 알아서 결정되기 때문에 더 나눠지지 않은채 다음과 같이 출력된다.

이는 다음 문장과 동일하다.

댓글
댓글 쓰기