데이터베이스 집합 연산자 - union / union all / intersect / minus
집합 연산자

다음 a와 b라는 두 개의 테이블이 있다. 이 테이블을 사용하여 집합 연산을 해보도록 하겠다.

union
가장 먼저 살펴볼 집합 연산은 union이다. union은 두 집합을 합치는 합집합이다. 이 때 중복된 데이터에 대해서는 제거한다. 따라서 위의 두 테이블은 C,D,E가 겹치기 때문에 3개의 중복이 제거된 7행만 출력된다.

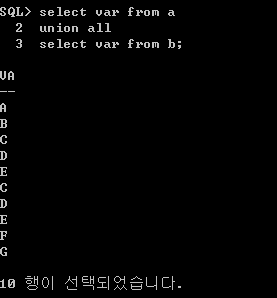
union all
union all은 union이 중복된 값들을 제거하는 것과 달리 중복을 허가한다. 따라서 각 테이블의 값이 모두 출력되어 10개의 행이 선택된다.
intersect
intersect는 교집합이다. 따라서 중복된 데이터만을 가져온다.

minus
minus는 차집합이다. 앞의 테이블에서 중복되는 것들만 제거하여 출력한다. 따라서 C, D, E가 제거된 A와 B만을 출력한다.

집합 연산자를 사용하기 위해서는 select문장에서 칼럼의 개수와 데이터 타입이 일치해야 한다. 그렇다면 칼럼의 개수가 맞지 않을 경우에는 이를 어떻게 처리해야 할까?
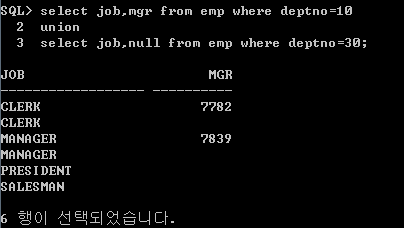
다음의 예시처럼 a 테이블에는 var 칼럼 뿐이지만, b는 var와 num 칼럼이 존재하기 때문에 다음처럼 오류가 발생한다.

이 때 부족한 칼럼에 null을 입력하여 두 select문 사이의 개수를 맞춘다. 이를 통해 부족한 칼럼에 대해서는 null값을 입력함으로써 집합 연산이 정상적으로 동작할 수 있도록 한다.

없는 데이터에 대해서는 null값이 출력되고 있음을 확인할 수 있다.
집합연산을 사용하면 다음처럼 새로운 테이블을 만드는 듯한 효과를 줄 수도 있다.
여러 개의 select문에 대해서 집합 연산을 사용하여 하나의 명령어로 사용할 수도 있다. 이를 통해서 여러 명령문으로 해결해야 할 문제도 한번의 해결이 가능하다.

이 예시에서 세 개의 select문이 사용되고 있다.
첫 번째 select문은 각 부서별 그리고 해당 부서에서 직책별 sal의 합을 나타낸다.
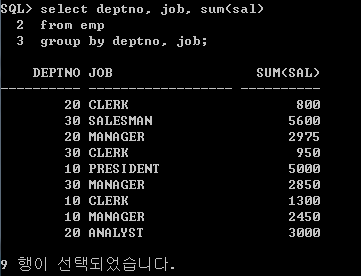
그리고 두 번째 select문은 각 부서별 sal의 합을 나타낸다.

마지막으로 세 번째 select문에서는 전체 sal의 합을 나타낸다.

이를 다 union(union all - 중복이 없어서 상관없음) 집합 연산을 통해서 구하면, 각 부서에 대해서 직책별 임금 합과 부서 전체 임금 합, 그리고 모든 부서에 대한 전체 임금 합이 하나의 테이블로 표현된다. 이에 대해서 deptno에 대해서 먼저 오름차순 정렬을 수행하고, job에 대해서 오름차순으로 정렬한다(기본 정렬은 오름차순).
*order by에서 1,2로 표현된 것은 order by를 공부할 때, 해당 칼럼명 대신에 칼럼 순서로도 정렬할 칼럼을 정할 수 있음을 배웠었다. 이를 참고하자.
댓글
댓글 쓰기